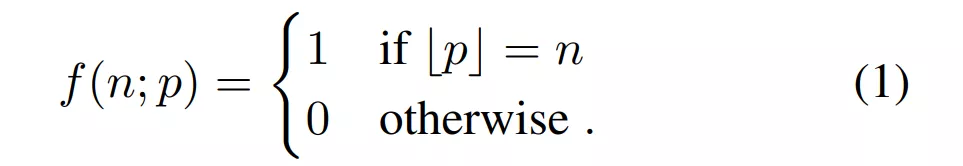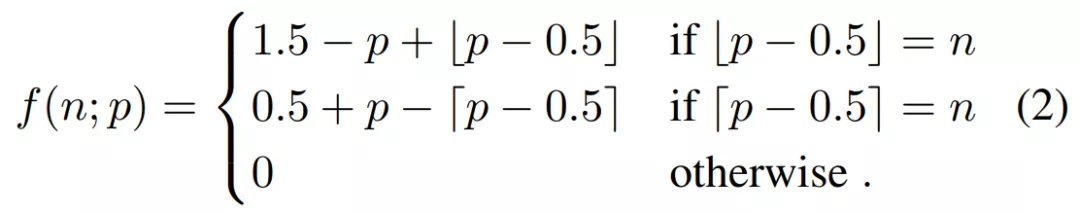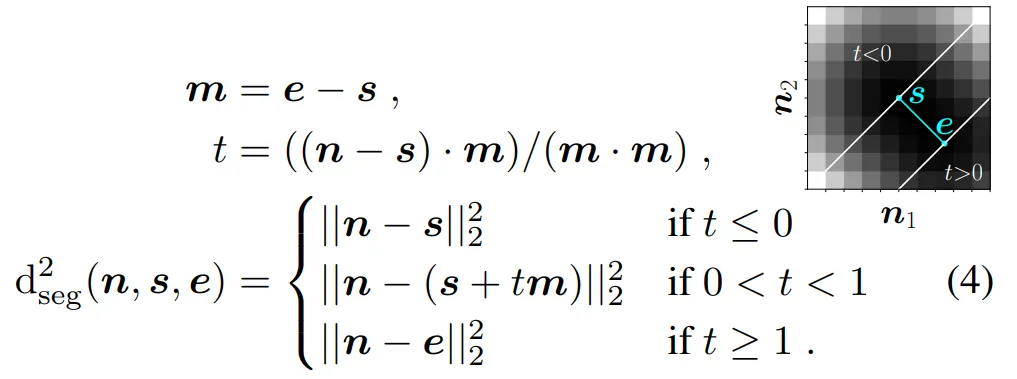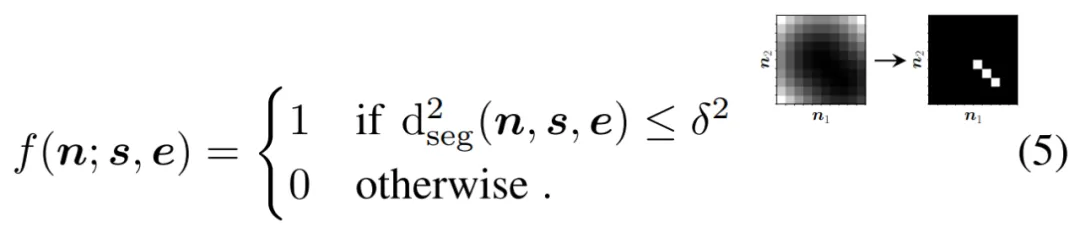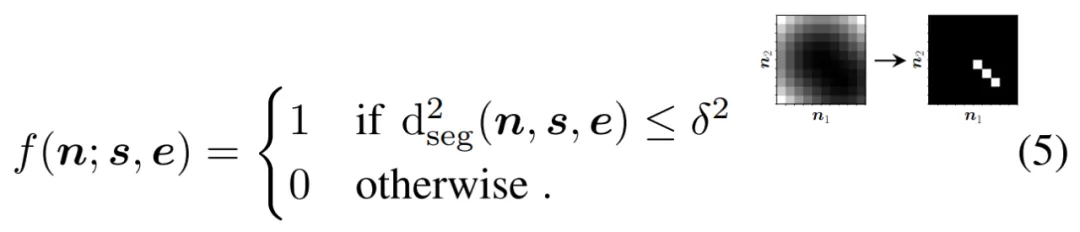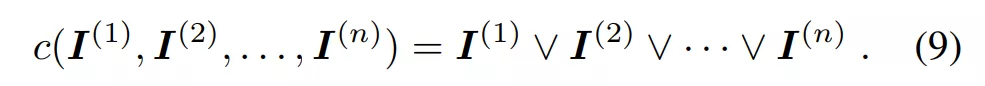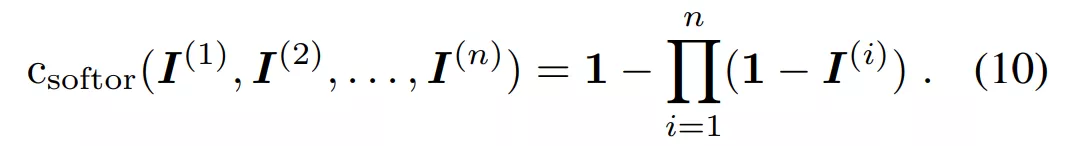在实现复杂且高精度图像编辑效果的同时,EditGAN 还能保持较高的图像质量和对象身份,英伟达在图像处理领域果然「出手不凡」。当前,AI 驱动的照片和图像编辑技术有助于简化摄影师和内容创作者的工作流程,并赋能更高水平的创意和数字艺术。基于 AI 的图像编辑工具也已经以神经照片编辑过滤器(filter)的形式应用在消费级软件上,并且深度学习研究社区积极地开发新的技术。其中,各式各样基于生成对抗网络(GAN)的模型和技术层出不穷,在实现原理上,领域研究人员要么将图像嵌入到 GAN 的隐空间,要么直接使用 GAN 生成图像。 大多数基于 GAN 的图像编辑方法分为以下几类。一些工作依赖于 GAN 在类标签或像素级语义分割注释上发挥作用,不同的条件会使输出结果出现变动;另一些工作使用辅助的属性分类器来指导图像的合成和编辑。然而,训练这种条件式 GAN 或外部分类器需要大规模的标注数据集。因此,这些方法目前仅适用于拥有大规模标注数据集的图像类型,如肖像等。即使拥有足够注释的数据集,大多数方法也仅能提供有限的编辑控制,这是因为这些注释通常仅包含高级的全局属性或者比较粗糙的像素级分割。 另一些方法专注于对不同图像的特征进行混合和插值,因此需要参照图像作为编辑目标,通常也无法提供微调控制。还有一些方法仔细剖析 GAN 的隐空间,找出适合编辑的解耦隐变量或者控制 GAN 的网络参数。但遗憾的是,这些方法无法实现精细的编辑,速度也通常较慢。 近日,英伟达、多伦多大学等机构在论文《EditGAN: High-Precision Semantic Image Editing》中克服了这些局限,并提出了一个全新的基于 GAN 的图像编辑框架 EditGAN——通过允许用户修改对象部件(object part)分割实现高精度的语义图像编辑。 相关研究已被 NeurIPS 2021 会议接收,代码和交互式编辑工具之后也会开源。
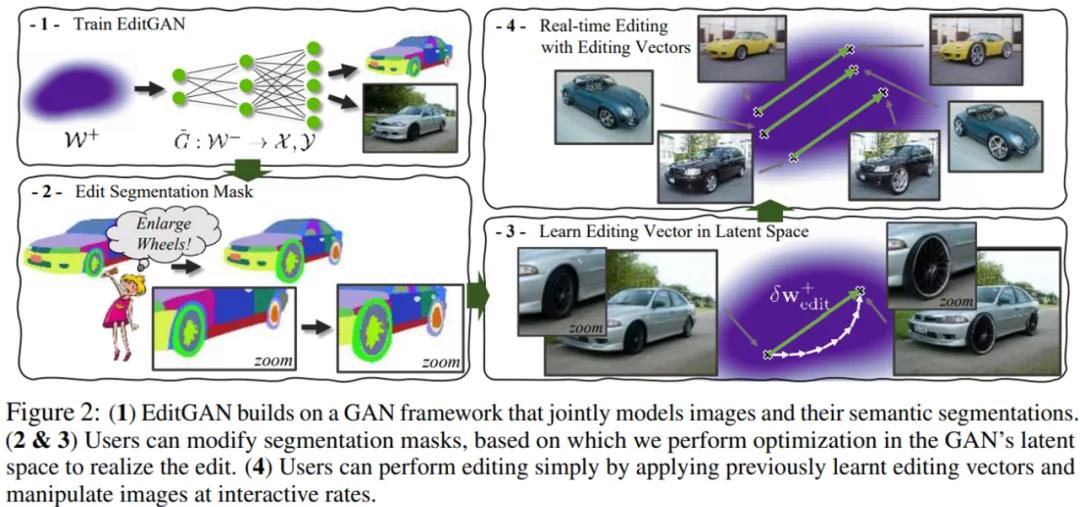
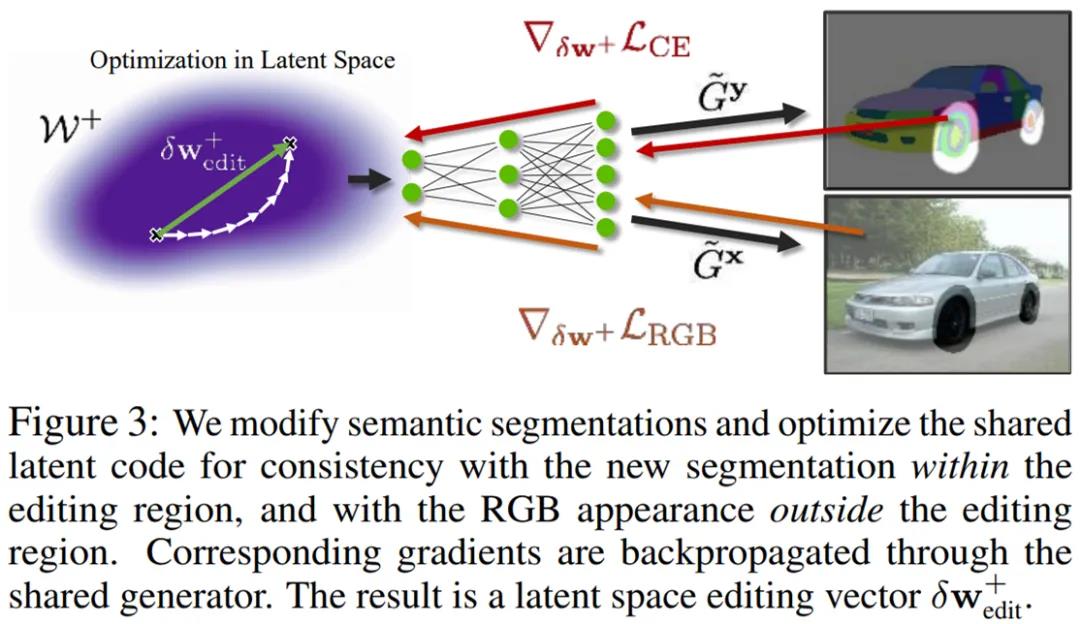
论文地址:https://arxiv.org/pdf/2111.03186.pdf项目主页:https://nv-tlabs.github.io/editGAN/ 具体而言,EditGAN 在最近提出的 GAN 模型基础上构建,不仅基于相同的潜在隐编码来共同地建模图像及其语义分割,而且仅需要 16 个标注示例,从而可以扩展至很多目标类和部件标签。研究者根据预期编辑结果来修改分割掩码,并优化隐编码以与新的分割保持一致,这样就可以高效地改变 RGB 图像。 此外,为了实现效率,他们通过学习隐空间中的编辑向量(editing vector)来实现编辑,并在无需或仅需少量额外优化步骤的情况下直接在其他图像上应用。因此,研究者预训练了一个感兴趣编辑的库以使得用户可以在交互工具中直接使用。 研究者表示,EditGAN 是首个同时实现以下目标的 GAN 驱动的图像编辑框架:
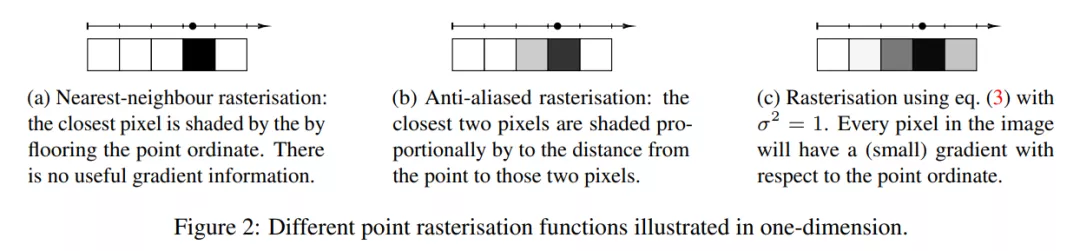
虽然论文与reddit项目作者的最终实现效果不同,论文是将图像抽象为点或线段的草图,项目则是将方块和圆形最终生成抽象人脸,但论文采用的方法对项目具有借鉴意义。因此,机器之心对论文《 Differentiable Drawing and Sketching 》中的技术细节进行了介绍。 技术解读:可微光栅化松弛 在这部分内容中,研究者讨论了如何将连续世界空间(continuous world space) W 中定义的点、线和曲线绘制或光栅化到图像空间中。 他们的目标是提出一种形式化方法(formalisation),使得最终可以定义相对于世界空间参数(如点坐标或线段起点和终点的坐标)可微的光栅化函数。 一维光栅化 研究者首先考虑了对一维点 p ϵ W 进行光栅化的问题,其中 W = R。具体来讲,点 p 的光栅化过程可以由函数 f(n; p) 来定义,该函数为图像空间中的每个像素计算一个值(通常为 [0 , 1])。这个图像空间的位置又由给出。 先来看看简单的最近像素(closest-pixel)光栅化函数。如果假设第 0 个像素覆盖点 p 的世界空间中的域 [0, 1),第一个像素覆盖 [1, 2) ,如此类推。然后,最近邻光栅化将真值点 p 映射到一个图像,如下等式(1)所示:
这一过程如下图 2a 所示。2b 则是另一种光栅化方案,其中在两个最近的像素上进行插值。
假设当被光栅化的点位于中点(midpoint)时,像素具有最大值,则如下等式(2)所示:
实际上,这些可以扩展至 2D 的函数在很多计算机图形系统中得到隐式地使用,但很少以我们编写它们的形式出现。 接下来是可微松弛。理想情况下,研究者希望能够定义一个相对于点 p 可微的光栅化函数,这允许 p 优化。等式(1)给出的光栅化函数对于 p 是分段可微的,但梯度几乎在所有地方都为零,这是没有用的。等式 (2) 在最邻近 p 的两个像素中具有一定的梯度,但总体而言它的梯度也几乎处处为零。 因此,研究者想定义一个光栅化函数,它对所有(或至少大部分)可能的 n 值都具有梯度。这个函数几乎在任何地方都应该是连续的和可微的。抗锯齿光栅化方法对如何实现这一点给出了一些提示:该函数可以根据 n 和 p 之间的距离为每个 n 计算一个值。 N 维中的松弛光栅化 以往定义的所有一维光栅化函数都可以简单地扩展为「在二维或更多维度上对一个点进行光栅化」。 线段可以通过其起始坐标 s = [s_x, s_y] 和结束坐标 e = [e_x, e_y] 来定义。为了开发一组通用、潜在可微的光栅化函数,研究者需要考虑光栅的形式化,就像在一维情况下所做的那样:找到一个函数,该函数在给定线段 f (n; s, e) 的情况下,能够在图像中所有像素位置集合 n 上定义一个标量场。 光栅化线段需要考虑像素与线段的接近程度。研究者高效地计算了任意像素 n 到线段上最近点的平方欧几里德距离,如下所示:







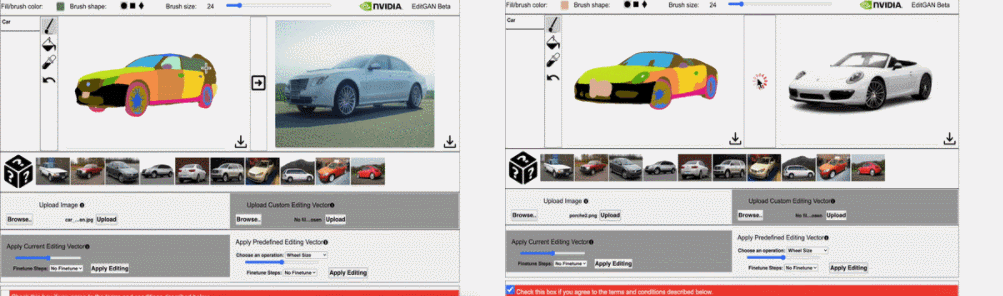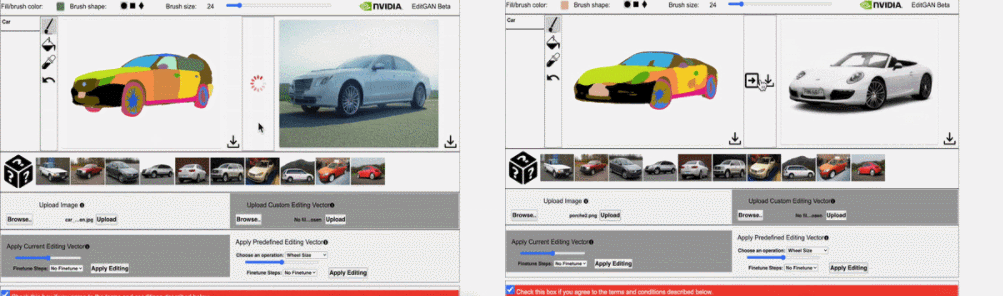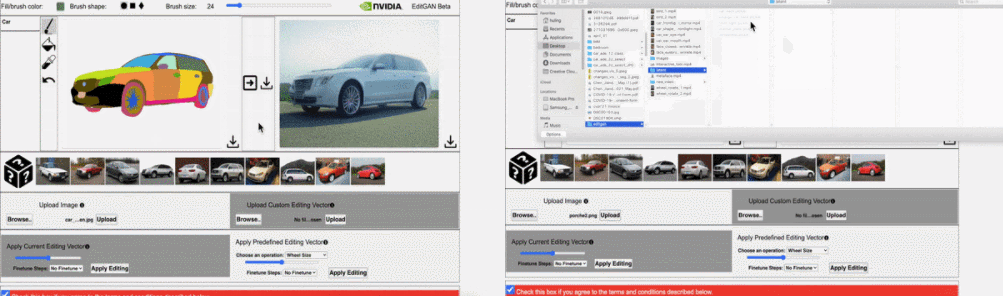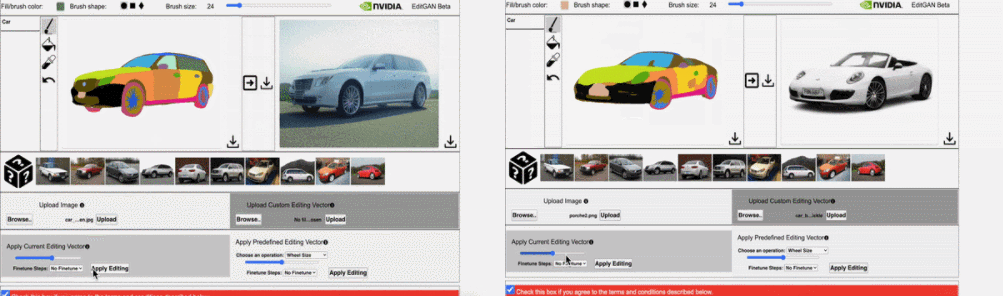
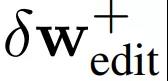 并执行 30 steps 的优化细化时,EditGAN 框架的图像编辑效果。结果显示,使用 EditGAN 的编辑操作保持了高图像质量并对所有类别的图像实现了良好的解耦。
并执行 30 steps 的优化细化时,EditGAN 框架的图像编辑效果。结果显示,使用 EditGAN 的编辑操作保持了高图像质量并对所有类别的图像实现了良好的解耦。


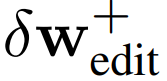 。接着嵌入域外 MetFaces 肖像(使用 100 steps 的优化),再通过 30 steps 的优化应用编辑向量。结果如下图 6 所示,该研究的编辑操作无缝地迁移至相差甚远的域外图像示例。
。接着嵌入域外 MetFaces 肖像(使用 100 steps 的优化),再通过 30 steps 的优化应用编辑向量。结果如下图 6 所示,该研究的编辑操作无缝地迁移至相差甚远的域外图像示例。







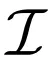 中。
中。 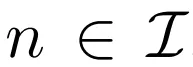 给出。
给出。